

At NVIDIA GTC25, Gnani.ai consultants unveiled groundbreaking developments in voice AI, specializing in the event and deployment of Speech-to-Speech Basis Fashions. This modern method guarantees to beat the restrictions of conventional cascaded voice AI architectures, ushering in an period of seamless, multilingual, and emotionally conscious voice interactions.
The Limitations of Cascaded Architectures
Present state-of-the-art structure powering voice brokers includes a three-stage pipeline: Speech-to-Textual content (STT), Massive Language Fashions (LLMs), and Textual content-to-Speech (TTS). Whereas efficient, this cascaded structure suffers from important drawbacks, primarily latency and error propagation. A cascaded structure has a number of blocks within the pipeline, and every block will add its personal latency. The cumulative latency throughout these phases can vary from 2.5 to three seconds, resulting in a poor consumer expertise. Furthermore, errors launched within the STT stage propagate via the pipeline, compounding inaccuracies. This conventional structure additionally loses essential paralinguistic options corresponding to sentiment, emotion, and tone, leading to monotonous and emotionally flat responses.
Introducing Speech-to-Speech Basis Fashions
To handle these limitations, Gnani.ai presents a novel Speech-to-Speech Basis Mannequin. This mannequin straight processes and generates audio, eliminating the necessity for intermediate textual content representations. The important thing innovation lies in coaching an enormous audio encoder with 1.5 million hours of labeled information throughout 14 languages, capturing nuances of emotion, empathy, and tonality. This mannequin employs a nested XL encoder, retrained with complete information, and an enter audio projector layer to map audio options into textual embeddings. For real-time streaming, audio and textual content options are interleaved, whereas non-streaming use circumstances make the most of an embedding merge layer. The LLM layer, initially primarily based on Llama 8B, was expanded to incorporate 14 languages, necessitating the rebuilding of tokenizers. An output projector mannequin generates mel spectrograms, enabling the creation of hyper-personalized voices.
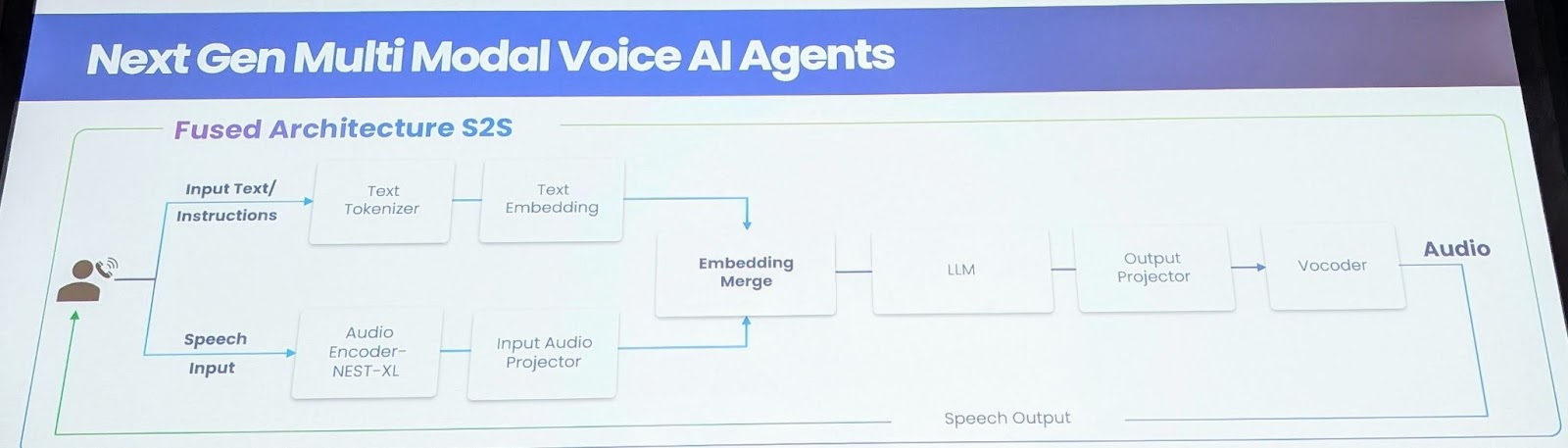
Key Advantages and Technical Hurdles
The Speech-to-Speech mannequin gives a number of important advantages. Firstly, it considerably reduces latency, shifting from 2 seconds to roughly 850-900 milliseconds for the primary token output. Secondly, it enhances accuracy by fusing ASR with the LLM layer, bettering efficiency, particularly for brief and lengthy speeches. Thirdly, the mannequin achieves emotional consciousness by capturing and modeling tonality, stress, and price of speech. Fourthly, it allows improved interruption dealing with via contextual consciousness, facilitating extra pure interactions. Lastly, the mannequin is designed to deal with low bandwidth audio successfully, which is essential for telephony networks. Constructing this mannequin offered a number of challenges, notably the large information necessities. The workforce created a crowd-sourced system with 4 million customers to generate emotionally wealthy conversational information. In addition they leveraged basis fashions for artificial information era and educated on 13.5 million hours of publicly out there information. The ultimate mannequin contains a 9 billion parameter mannequin, with 636 million for the audio enter, 8 billion for the LLM, and 300 million for the TTS system.
NVIDIA’s Position in Improvement
The event of this mannequin was closely reliant on the NVIDIA stack. NVIDIA Nemo was used for coaching encoder-decoder fashions, and NeMo Curator facilitated artificial textual content information era. NVIDIA EVA was employed to generate audio pairs, combining proprietary info with artificial information.
Use Circumstances
Gnani.ai showcased two main use circumstances: real-time language translation and buyer assist. The true-time language translation demo featured an AI engine facilitating a dialog between an English-speaking agent and a French-speaking buyer. The shopper assist demo highlighted the mannequin’s capability to deal with cross-lingual conversations, interruptions, and emotional nuances.
Speech-to-Speech Basis Mannequin
The Speech-to-Speech Basis Mannequin represents a major leap ahead in voice AI. By eliminating the restrictions of conventional architectures, this mannequin allows extra pure, environment friendly, and emotionally conscious voice interactions. Because the know-how continues to evolve, it guarantees to remodel numerous industries, from customer support to world communication.

Jean-marc is a profitable AI enterprise government .He leads and accelerates development for AI powered options and began a pc imaginative and prescient firm in 2006. He’s a acknowledged speaker at AI conferences and has an MBA from Stanford.