

Lengthy-chain reasoning is among the most compute-intensive duties in fashionable massive language fashions. When a mannequin like DeepSeek-R1 or Qwen3 works by way of a fancy math drawback, it may well generate tens of hundreds of tokens earlier than arriving at a solution. Each a type of tokens should be saved in what is known as the KV cache — a reminiscence construction that holds the Key and Worth vectors the mannequin must attend again to throughout era. The longer the reasoning chain, the bigger the KV cache grows, and for a lot of deployment eventualities, particularly on shopper {hardware}, this progress finally exhausts GPU reminiscence completely.
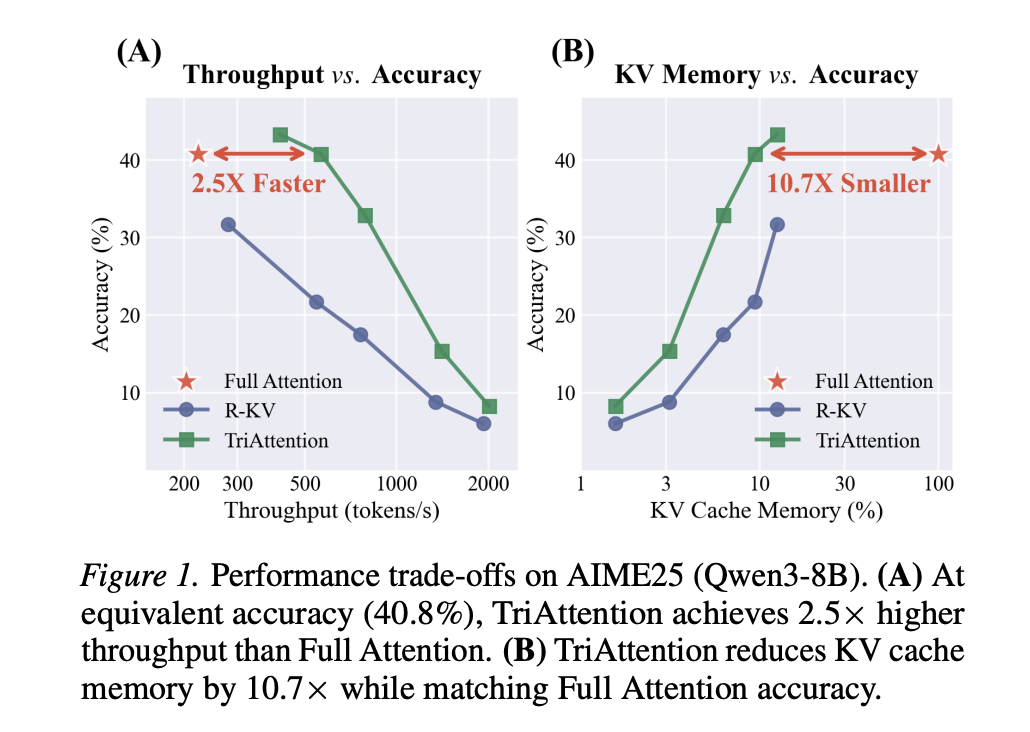
A workforce of researchers from MIT, NVIDIA, and Zhejiang College proposed a technique referred to as TriAttention that immediately addresses this drawback. On the AIME25 mathematical reasoning benchmark with 32K-token era, TriAttention matches Full Consideration accuracy whereas reaching 2.5× larger throughput or 10.7× KV reminiscence discount. Main baselines obtain solely about half the accuracy on the identical effectivity degree.
The Drawback with Current KV Cache Compression
To grasp why TriAttention is necessary, it helps to grasp the usual method to KV cache compression. Most present strategies — together with SnapKV, H2O, and R-KV — work by estimating which tokens within the KV cache are necessary and evicting the remainder. Significance is usually estimated by consideration scores: if a key receives excessive consideration from latest queries, it’s thought-about necessary and saved.
The catch is that these strategies function in what the analysis workforce calls post-RoPE house. RoPE, or Rotary Place Embedding, is the positional encoding scheme utilized by most fashionable LLMs together with Llama, Qwen, and Mistral. RoPE encodes place by rotating the Question and Key vectors in a frequency-dependent approach. Consequently, a question vector at place 10,000 appears to be like very totally different from the identical semantic question at place 100, as a result of its path has been rotated by the place encoding.
This rotation signifies that solely essentially the most just lately generated queries have orientations which can be ‘updated’ for estimating which keys are necessary proper now. Prior work has confirmed this empirically: rising the remark window for significance estimation doesn’t assist — efficiency peaks at round 25 queries and declines after that. With such a tiny window, some keys that can turn into necessary later get completely evicted.
This drawback is very acute for what the analysis workforce calls retrieval heads — consideration heads whose operate is to retrieve particular factual tokens from lengthy contexts. The related tokens for a retrieval head can stay dormant for hundreds of tokens earlier than all of a sudden changing into important to the reasoning chain. Publish-RoPE strategies, working over a slim remark window, see low consideration on these tokens through the dormant interval and completely evict them. When the mannequin later must recall that info, it’s already gone, and the chain of thought breaks.
The Pre-RoPE Remark: Q/Okay Focus
The important thing perception in TriAttention comes from Question and Key vectors earlier than RoPE rotation is utilized — the pre-RoPE house. When the analysis workforce visualized Q and Okay vectors on this house, they discovered one thing constant and placing: throughout the overwhelming majority of consideration heads and throughout a number of mannequin architectures, each Q and Okay vectors cluster tightly round fastened, non-zero heart factors. The analysis workforce phrases this property Q/Okay focus, and measures it utilizing the Imply Resultant Size R — an ordinary directional statistics measure the place R → 1 means tight clustering and R → 0 means dispersion in all instructions.
On Qwen3-8B, roughly 90% of consideration heads exhibit R > 0.95, which means their pre-RoPE Q/Okay vectors are practically completely concentrated round their respective facilities. Critically, these facilities are steady throughout totally different token positions and throughout totally different enter sequences — they’re an intrinsic property of the mannequin’s discovered weights, not a property of any explicit enter. The analysis workforce additional affirm that Q/Okay focus is domain-agnostic: measuring Imply Resultant Size throughout Math, Coding, and Chat domains on Qwen3-8B yields practically equivalent values of 0.977–0.980.
This stability is what post-RoPE strategies can not exploit. RoPE rotation disperses these concentrated vectors into arc patterns that adjust with place. However in pre-RoPE house, the facilities stay fastened.
From Focus to a Trigonometric Sequence
The analysis workforce then present mathematically that when Q and Okay vectors are concentrated round their facilities, the eye logit — the uncooked rating earlier than softmax that determines how a lot a question attends to a key — simplifies dramatically. Substituting the Q/Okay facilities into the RoPE consideration method, the logit reduces to a operate that relies upon solely on the Q-Okay distance (the relative positional hole between question and key), expressed as a trigonometric sequence:
Right here, Δ is the positional distance, ωf are the RoPE rotation frequencies for every frequency band f, and the coefficients af and bf are decided by the Q/Okay facilities. This sequence produces a attribute attention-vs-distance curve for every head. Some heads want close by keys (native consideration), others want very distant keys (consideration sinks). The facilities, computed offline from calibration knowledge, totally decide which distances are most well-liked.
The analysis workforce validated this experimentally throughout 1,152 consideration heads in Qwen3-8B and throughout Qwen2.5 and Llama3 architectures. The Pearson correlation between the anticipated trigonometric curve and the precise consideration logits has a imply above 0.5 throughout all heads, with many heads reaching correlations of 0.6–0.9. The analysis workforce additional validates this on GLM-4.7-Flash, which makes use of Multi-head Latent Consideration (MLA) reasonably than normal Grouped-Question Consideration — a meaningfully totally different consideration structure. On MLA, 96.6% of heads exhibit R > 0.95, in comparison with 84.7% for GQA, confirming that Q/Okay focus just isn’t particular to 1 consideration design however is a normal property of contemporary LLMs.
How TriAttention Makes use of This
TriAttention is a KV cache compression methodology that makes use of these findings to attain keys with no need any dwell question observations. The scoring operate has two elements:
The Trigonometric Sequence Rating (Strig) makes use of the Q heart computed offline and the precise cached key illustration to estimate how a lot consideration the important thing will obtain, based mostly on its positional distance from future queries. As a result of a key could also be attended to by queries at many future positions, TriAttention averages this rating over a set of future offsets utilizing geometric spacing.
The Norm-Primarily based Rating (Snorm) handles the minority of consideration heads the place Q/Okay focus is decrease. It weights every frequency band by the anticipated question norm contribution, offering complementary details about token salience past distance desire alone.
The 2 scores are mixed utilizing the Imply Resultant Size R as an adaptive weight: when focus is excessive, Strig dominates; when focus is decrease, Snorm contributes extra. Each 128 generated tokens, TriAttention scores all keys within the cache and retains solely the top-B, evicting the remainder.
Outcomes on Mathematical Reasoning
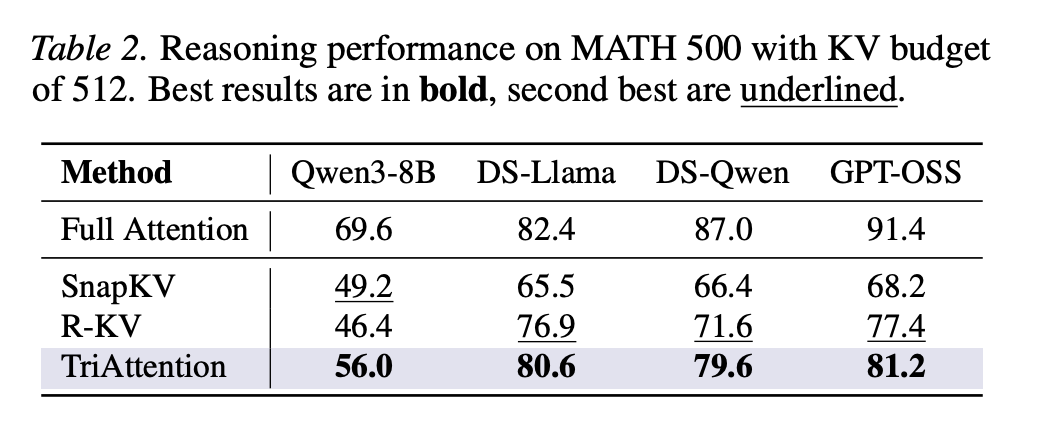
On AIME24 with Qwen3-8B, TriAttention achieves 42.1% accuracy in opposition to Full Consideration’s 57.1%, whereas R-KV achieves solely 25.4% on the identical KV price range of two,048 tokens. On AIME25, TriAttention achieves 32.9% versus R-KV’s 17.5% — a 15.4 proportion level hole. On MATH 500 with only one,024 tokens within the KV cache out of a attainable 32,768, TriAttention achieves 68.4% accuracy in opposition to Full Consideration’s 69.6%.

The analysis workforce additionally introduces a Recursive State Question benchmark based mostly on recursive simulation utilizing depth-first search. Recursive duties stress reminiscence retention as a result of the mannequin should preserve intermediate states throughout lengthy chains and backtrack to them later — if any intermediate state is evicted, the error propagates by way of all subsequent return values, corrupting the ultimate outcome. Underneath average reminiscence stress as much as depth 16, TriAttention performs comparably to Full Consideration, whereas R-KV exhibits catastrophic accuracy degradation — dropping from roughly 61% at depth 14 to 31% at depth 16. This means R-KV incorrectly evicts crucial intermediate reasoning states.
On throughput, TriAttention achieves 1,405 tokens per second on MATH 500 in opposition to Full Consideration’s 223 tokens per second, a 6.3× speedup. On AIME25, it achieves 563.5 tokens per second in opposition to 222.8, a 2.5× speedup at matched accuracy.
Generalization Past Mathematical Reasoning
The outcomes lengthen properly past math benchmarks. On LongBench — a 16-subtask benchmark overlaying query answering, summarization, few-shot classification, retrieval, counting, and code duties — TriAttention achieves the very best common rating of 48.1 amongst all compression strategies at a 50% KV price range on Qwen3-8B, profitable 11 out of 16 subtasks and surpassing the subsequent greatest baseline, Ada-KV+SnapKV, by 2.5 factors. On the RULER retrieval benchmark at a 4K context size, TriAttention achieves 66.1, a ten.5-point hole over SnapKV. These outcomes affirm that the strategy just isn’t tuned to mathematical reasoning alone — the underlying Q/Okay focus phenomenon transfers to normal language duties.
Key Takeaways
- Current KV cache compression strategies have a basic blind spot: Strategies like SnapKV and R-KV estimate token significance utilizing latest post-RoPE queries, however as a result of RoPE rotates question vectors with place, solely a tiny window of queries is usable. This causes necessary tokens — particularly these wanted by retrieval heads — to be completely evicted earlier than they turn into crucial.
- Pre-RoPE Question and Key vectors cluster round steady, fastened facilities throughout practically all consideration heads: This property, referred to as Q/Okay focus, holds no matter enter content material, token place, or area, and is constant throughout Qwen3, Qwen2.5, Llama3, and even Multi-head Latent Consideration architectures like GLM-4.7-Flash.
- These steady facilities make consideration patterns mathematically predictable with out observing any dwell queries: When Q/Okay vectors are concentrated, the eye rating between any question and key reduces to a operate that relies upon solely on their positional distance — encoded as a trigonometric sequence. TriAttention makes use of this to attain each cached key offline utilizing calibration knowledge alone.
- TriAttention matches Full Consideration reasoning accuracy at a fraction of the reminiscence and compute price: On AIME25 with 32K-token era, it achieves 2.5× larger throughput or 10.7× KV reminiscence discount whereas matching Full Consideration accuracy — practically doubling R-KV’s accuracy on the identical reminiscence price range throughout each AIME24 and AIME25.
- The strategy generalizes past math and works on shopper {hardware}. TriAttention outperforms all baselines on LongBench throughout 16 normal NLP subtasks and on the RULER retrieval benchmark, and permits a 32B reasoning mannequin to run on a single 24GB RTX 4090 by way of OpenClaw — a process that causes out-of-memory errors beneath Full Consideration.
Take a look at the Paper, Repo and Mission Web page. Additionally, be happy to observe us on Twitter and don’t overlook to hitch our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be part of us on telegram as properly.
Must companion with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and so on.? Join with us