

TL;DR: Skala is a deep-learning trade–correlation practical for Kohn–Sham Density Practical Idea (DFT) that targets hybrid-level accuracy at semi-local value, reporting MAE ≈ 1.06 kcal/mol on W4-17 (0.85 on the single-reference subset) and WTMAD-2 ≈ 3.89 kcal/mol on GMTKN55; evaluations use a set D3(BJ) dispersion correction. It’s positioned for main-group molecular chemistry right now, with transition metals and periodic techniques slated as future extensions. Azure AI Foundry The mannequin and tooling can be found now through Azure AI Foundry Labs and the open-source microsoft/skala repository.
How a lot compression ratio and throughput would you recuperate by coaching a format-aware graph compressor and delivery solely a self-describing graph to a common decoder? Microsoft Analysis has launched Skala, a neural trade–correlation (XC) practical for Kohn–Sham Density Practical Idea (DFT). Skala learns non-local results from knowledge whereas retaining the computational profile akin to meta-GGA functionals.
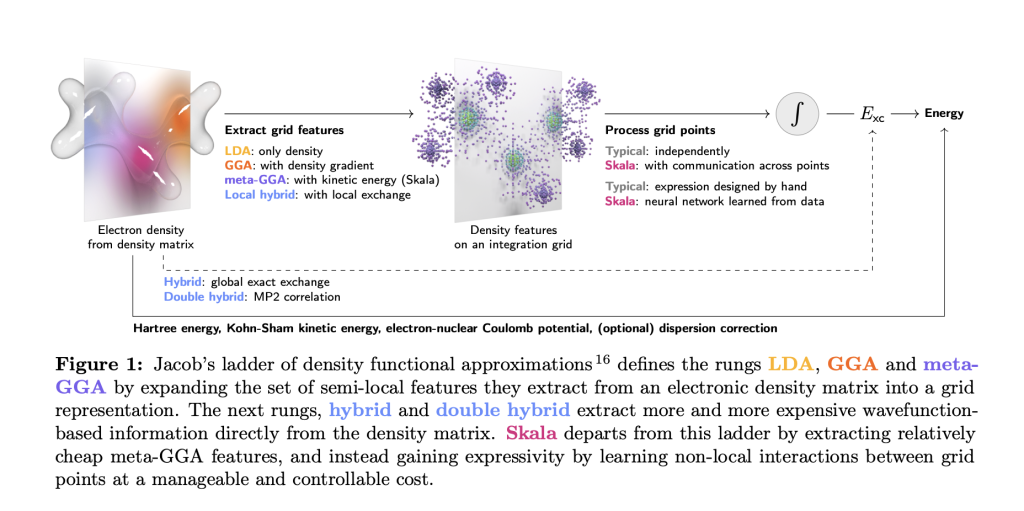
What Skala is (and isn’t)?
Skala replaces a home made XC kind with a neural practical evaluated on commonplace meta-GGA grid options. It explicitly doesn’t try to be taught dispersion on this first launch; benchmark evaluations use a set D3 correction (D3(BJ) except famous). The purpose is rigorous main-group thermochemistry at semi-local value, not a common practical for all regimes on day one.
Benchmarks
On W4-17 atomization energies, Skala experiences MAE 1.06 kcal/mol on the total set and 0.85 kcal/mol on the single-reference subset. On GMTKN55, Skala achieves WTMAD-2 3.89 kcal/mol, aggressive with high hybrids; all functionals have been evaluated with the identical dispersion settings (D3(BJ) except VV10/D3(0) applies).


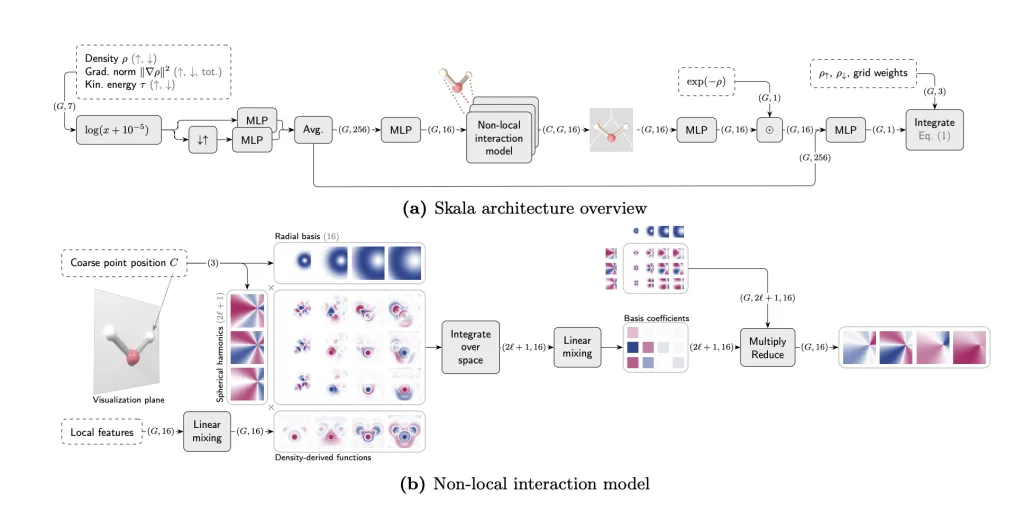
Structure and coaching
Skala evaluates meta-GGA options on the usual numerical integration grid, then aggregates info through a finite-range, non-local neural operator (bounded enhancement issue; exact-constraint conscious together with Lieb–Oxford, size-consistency, and coordinate-scaling). Coaching proceeds in two phases: (1) pre-training on B3LYP densities with XC labels extracted from high-level wavefunction energies; (2) SCF-in-the-loop fine-tuning utilizing Skala’s personal densities (no backprop via SCF).
The mannequin is educated on a big, curated corpus dominated by ~80k high-accuracy complete atomization energies (MSR-ACC/TAE) plus extra reactions/properties, with W4-17 and GMTKN55 faraway from coaching to keep away from leakage.
Value profile and implementation
Skala retains semi-local value scaling and is engineered for GPU execution through GauXC; the general public repo exposes: (i) a PyTorch implementation and microsoft-skala PyPI bundle with PySCF/ASE hooks, and (ii) a GauXC add-on usable to combine Skala into different DFT stacks. The README lists ~276k parameters and gives minimal examples.
Utility
In follow, Skala slots into main-group molecular workflows the place semi-local value and hybrid-level accuracy matter: high-throughput response energetics (ΔE, barrier estimates), conformer/radical stability rating, and geometry/dipole predictions feeding QSAR/lead-optimization loops. As a result of it’s uncovered through PySCF/ASE and a GauXC GPU path, groups can run batched SCF jobs and display screen candidates at close to meta-GGA runtime, then reserve hybrids/CC for last checks. For managed experiments and sharing, Skala is offered in Azure AI Foundry Labs and as an open GitHub/PyPI stack.
Key Takeaways
- Efficiency: Skala achieves MAE 1.06 kcal/mol on W4-17 (0.85 on the single-reference subset) and WTMAD-2 3.89 kcal/mol on GMTKN55; dispersion is utilized through D3(BJ) in reported evaluations.
- Methodology: A neural XC practical with meta-GGA inputs and finite-range realized non-locality, honoring key actual constraints; retains semi-local O(N³) value and doesn’t be taught dispersion on this launch.
- Coaching sign: Skilled on ~150k high-accuracy labels, together with ~80k CCSD(T)/CBS-quality atomization energies (MSR-ACC/TAE); SCF-in-the-loop fine-tuning makes use of Skala’s personal densities; public check units are de-duplicated from coaching.
Skala is a practical step: a neural XC practical reporting MAE 1.06 kcal/mol on W4-17 (0.85 on single-reference) and WTMAD-2 3.89 kcal/mol on GMTKN55, evaluated with D3(BJ) dispersion, and scoped right now to main-group molecular techniques. It’s accessible for testing through Azure AI Foundry Labs with code and PySCF/ASE integrations on GitHub, enabling direct head-to-head baselines towards present meta-GGAs and hybrids.
Take a look at the Technical Paper, GitHub Web page and technical weblog. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be a part of us on telegram as effectively.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.