

Run Google’s newest omni-capable open fashions quicker on NVIDIA RTX AI PCs, from NVIDIA Jetson Orin Nano, GeForce RTX desktops to the brand new DGX Spark, to construct customized, always-on AI assistants like OpenClaw with out paying an enormous “token tax” for each motion.
The panorama of recent AI is shifting quickly. We’re transferring away from a complete reliance on huge, generalized cloud fashions and getting into the period of native, agentic AI powered by platforms like OpenClaw. Whether or not it’s deploying a vision-enabled assistant on an edge gadget or constructing an always-on agent that automates advanced coding workflows, the potential for generative AI on native {hardware} is totally boundless.
Nevertheless, builders face a persistent bottleneck and an enormous hidden monetary burden: The “Token Tax.” How do you get an AI to continually course of multimodal inputs quickly and reliably with out racking up astronomical cloud computing payments for each single token generated?
The reply to eliminating API prices fully is the brand new Google Gemma 4 household, and the optimum {hardware} platform of alternative is NVIDIA GPUs.
Google’s newest additions to the Gemma 4 household introduce a category of small, quick, and omni-capable fashions constructed explicitly for environment friendly native execution throughout a variety of gadgets. Optimized in collaboration with NVIDIA, these fashions scale effortlessly from the Jetson Orin Nano edge AI modules to GeForce RTX PCs, workstations, and the DGX Spark private AI supercomputer.
The Agentic AI Paradigm
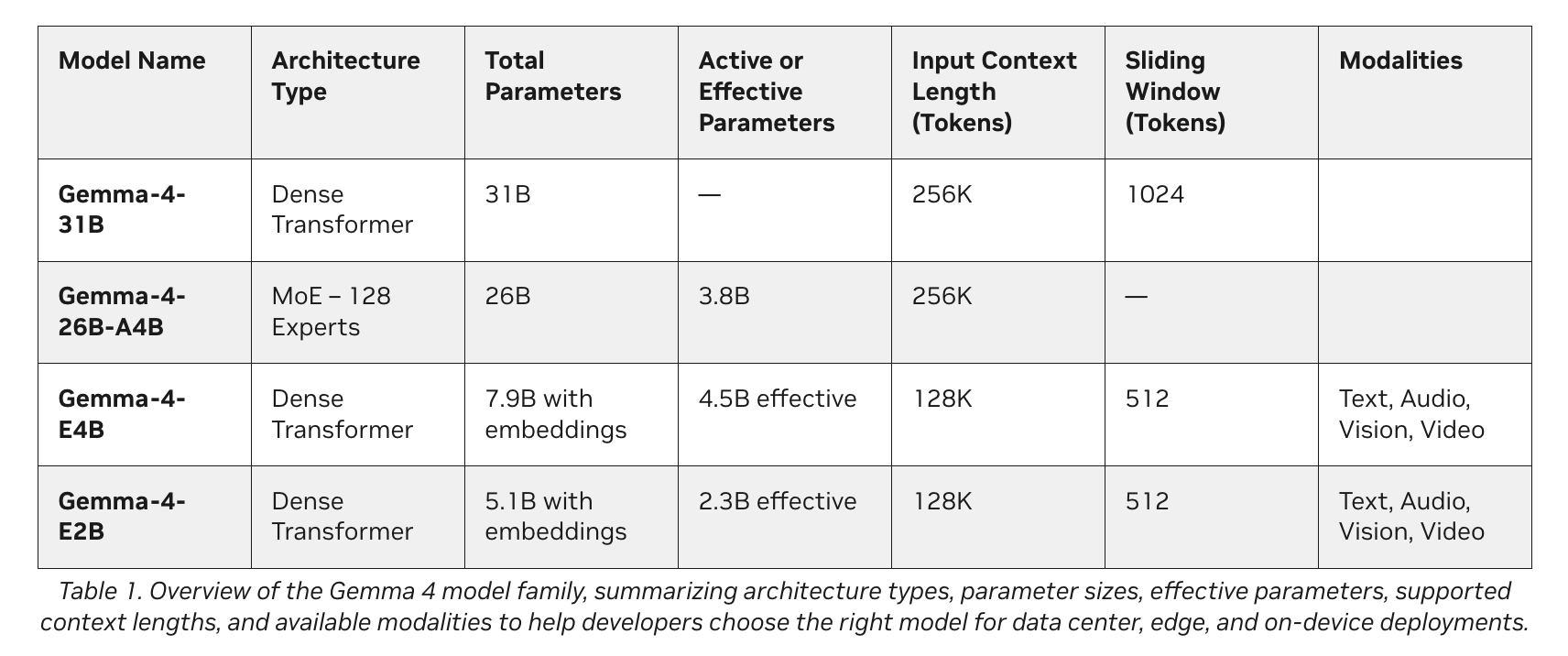
Consider the Gemma 4 household as a high-performance engine to your native AI brokers. Spanning E2B, E4B, 26B, and 31B variants, these fashions are designed for environment friendly deployment anyplace. They natively assist structured software use (perform calling) for brokers and provide interleaved multimodal inputs, that means builders can combine textual content and pictures in any order inside a single immediate.
Relying in your {hardware} and objectives, builders usually make the most of certainly one of two foremost tiers:
1. Extremely-Environment friendly Edge Fashions (E2B and E4B)
- The Tech: Gemma 4 E2B and E4B.
- The way it Works: These fashions are constructed for ultraefficient, low-latency inference on the edge. They function fully offline with near-zero latency and nil API charges.
- Greatest For: IoT gadgets, robotics, and localized sensor networks.
- {Hardware} Wanted: Gadgets together with NVIDIA Jetson Orin Nano modules.
2. Excessive-Efficiency Agentic Fashions (26B and 31B)
- The Tech: Gemma 4 26B and 31B.
- The way it Works: These variants are designed particularly for high-performance reasoning and developer-centric workflows.
- Greatest For: Advanced problem-solving, code technology, and operating agentic AI.
- {Hardware} Wanted: NVIDIA RTX GPUs, workstations, and DGX Spark methods.
The {Hardware} Actuality: Why NVIDIA Accelerates Gemma 4
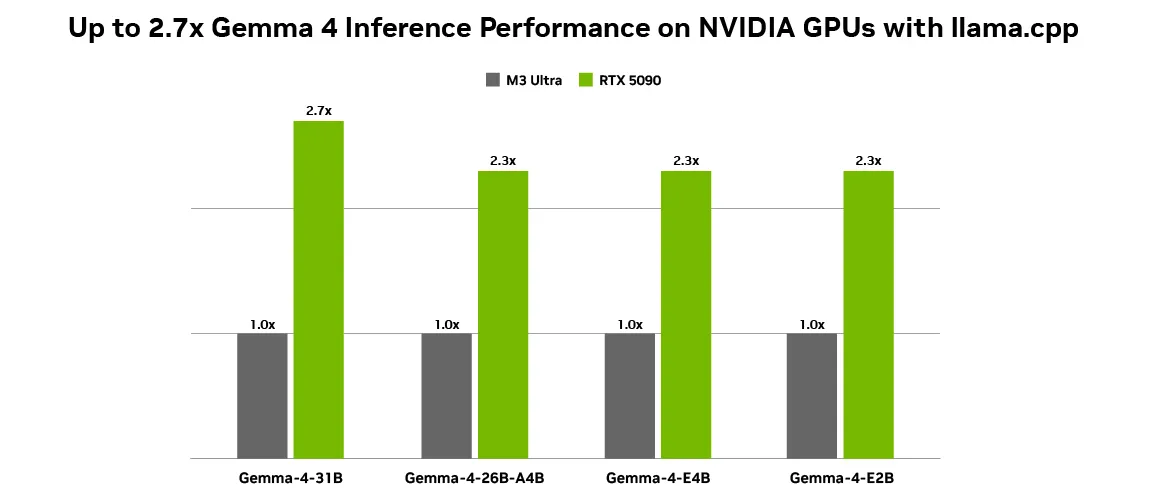
Some of the crucial components in making native AI financially viable is token technology throughput. Operating open fashions just like the Gemma 4 household on NVIDIA GPUs achieves optimum efficiency as a result of NVIDIA Tensor Cores speed up AI inference workloads, delivering greater throughput and decrease latency. With as much as 2.7x inference efficiency positive aspects on an RTX 5090 in comparison with an M3 Extremely desktop utilizing llama.cpp, native execution is smoother than ever. This unimaginable pace makes zero-cost native inference viable for heavy, steady agentic workloads.
OpenClaw & The “Token Tax” Answer
Why is the mixture of Gemma 4 and NVIDIA successful the native AI race? It comes down to hurry and economics.
As native agentic AI positive aspects momentum, functions like OpenClaw are enabling always-on AI assistants on RTX PCs, workstations, and DGX Spark methods. The most recent Gemma 4 fashions are totally appropriate with OpenClaw, permitting customers to construct succesful native brokers that repeatedly draw context from private information, functions, and workflows to automate day by day duties.
For an always-on assistant like OpenClaw, operating quick and regionally isn’t only a technical desire; it’s an financial necessity. Should you have been to make use of a cloud API to learn each private file, analyze display screen context, and course of 1000’s of automated actions an hour, the ensuing “Token Tax” can be astronomical. Paying a cloud supplier for each single token generated by a continually energetic background agent is financially unsustainable. By operating Gemma 4 regionally on an NVIDIA GPU, customers eradicate these API token prices fully. You get infinite, lightning-fast, zero-latency inference that makes an always-on AI really feel like a local, cost-free extension of your working system.
Making It Safe: Meet NeMoClaw
Whereas OpenClaw is a implausible working system for private AI, enterprise and privacy-conscious customers require stricter boundaries. To make these setups safe, builders can use NVIDIA NeMoClaw. NeMoClaw is an open-source stack that provides important privateness and safety controls to OpenClaw. With a single command, anybody can run always-on, self-evolving brokers safely. Utilizing the NVIDIA Agent Toolkit and OpenShell, NeMoClaw enforces policy-based guardrails, giving customers complete management over how their brokers deal with delicate knowledge. This pairs completely with native Nemotron or Gemma fashions to maintain knowledge fully offline, avoiding each cloud knowledge leaks and cloud API token fees.
Use Case Research 1: The “At all times-On” Developer Assistant
- The Objective: Run an always-on coding assistant that continually displays a developer’s workflow to counsel code optimizations, debug errors in real-time, and automate developer workflows.
- The Downside: Utilizing cloud fashions for this creates a crippling token tax, because the assistant repeatedly reads a whole bunch of traces of code each minute. Moreover, importing proprietary codebase snippets to the cloud creates safety and IP dangers.
- The Answer: Operating Gemma 4 (31B variant) paired with OpenClaw regionally on an NVIDIA GeForce RTX 5090 desktop.
- The End result: The developer receives immediate, zero-latency code technology and debugging. As a result of it runs regionally, 1000’s of {dollars} in potential API token prices are fully eradicated, and proprietary code by no means leaves the workstation.
Use Case Research 2: The Edge Imaginative and prescient Agent
- The Objective: Deploy sensible safety cameras in a distant warehouse able to monitoring stock and figuring out hazards in real-time utilizing doc and video intelligence.
- The Downside: Streaming 24/7 video feeds to a cloud imaginative and prescient mannequin incurs an astronomical token tax and requires huge bandwidth. Normal native fashions are too giant to suit on edge gadgets.
- The Answer: Deploying the Gemma 4 E2B mannequin on an NVIDIA Jetson Orin Nano edge AI module. The mannequin makes use of its wealthy imaginative and prescient and video capabilities to course of interleaved multimodal inputs seamlessly on-device.
- The End result: The system achieves ultraefficient, low-latency inference fully offline. It acknowledges objects and analyzes video repeatedly 24/7 with out producing a single cent in API token charges.
Use Case Research 3: The Safe Monetary Agent
- The Objective: Create a private assistant that automates tax preparation and opinions delicate banking paperwork throughout 35+ languages.
- The Downside: Monetary data can’t be uncovered to cloud fashions attributable to extreme privateness laws, and processing a whole bunch of pages of textual content generates a excessive token tax.
- The Answer: The consumer makes use of NeMoClaw on an NVIDIA DGX Spark to wrap the always-on agent in strict, policy-based privateness guardrails. The agent makes use of the Gemma 4 26B mannequin for its robust efficiency on advanced problem-solving and reasoning duties.
- The End result: A extremely safe, succesful agent that pulls context from private monetary information safely. NeMoClaw ensures the agent strictly adheres to privateness guidelines, retaining all banking knowledge offline, quick, protected, and free from cloud processing charges.
Able to Begin?
NVIDIA, Google, and the open-source neighborhood have offered complete instruments to get you operating and saving on API prices instantly.
- For Desktop Customers: NVIDIA has collaborated with Ollama and llama.cpp to offer one of the best native deployment expertise. Obtain Ollama to run Gemma 4 natively, or set up llama.cpp paired with the Gemma 4 GGUF Hugging Face checkpoint.
- For At all times-On Brokers: Learn to run OpenClaw free of charge on RTX GPUs and DGX Spark or by utilizing the DGX Spark OpenClaw playbook.
Try the Google DeepMind announcement weblog and the NVIDIA technical weblog for extra particulars on find out how to get began with Gemma 4 on NVIDIA GPUs.
Observe:Because of the NVIDIA AI staff for the thought management/ Sources for this text. NVIDIA AI staff has supported this content material/article for promotion.

Jean-marc is a profitable AI enterprise govt .He leads and accelerates development for AI powered options and began a pc imaginative and prescient firm in 2006. He’s a acknowledged speaker at AI conferences and has an MBA from Stanford.